World Models and Zero‑Shot Planning: The Imagination Engine for Physical AI
How predictive, action-conditioned simulation enables grounded reasoning and planning—complementing language models with a deeper sense of reality.
1. The Need for Grounded Intelligence
Language models have transformed what machines can do with text. They can summarise, translate, code, and answer questions with remarkable fluency. Yet there is a growing recognition—particularly from researchers building robots and autonomous systems—that linguistic ability alone does not provide the kind of understanding needed to act reliably in the physical world.
> “A robot‑rich future requires AIs that understand the physical world and anticipate the consequences of their actions. Language models alone are not designed for this.”
This is not a dismissal of LLMs. It is an observation about capability gaps: long‑horizon planning, spatial reasoning, manipulating novel objects, and safe operation in open, dynamic environments all require something that text‑only training does not reliably impart. That something is an internal world model—a predictive simulation of how the world’s state evolves under different actions.
World models are not a replacement for language models. They are a complementary component, providing the grounded, action‑conditioned predictive substrate that transforms an AI from a text-bound reasoner into an embodied planner. This article explores how that works, why zero‑shot planning is the killer application, and what the current state of the art—from JEPA‑style latent prediction to interactive generative simulators—looks like in early 2026.
---
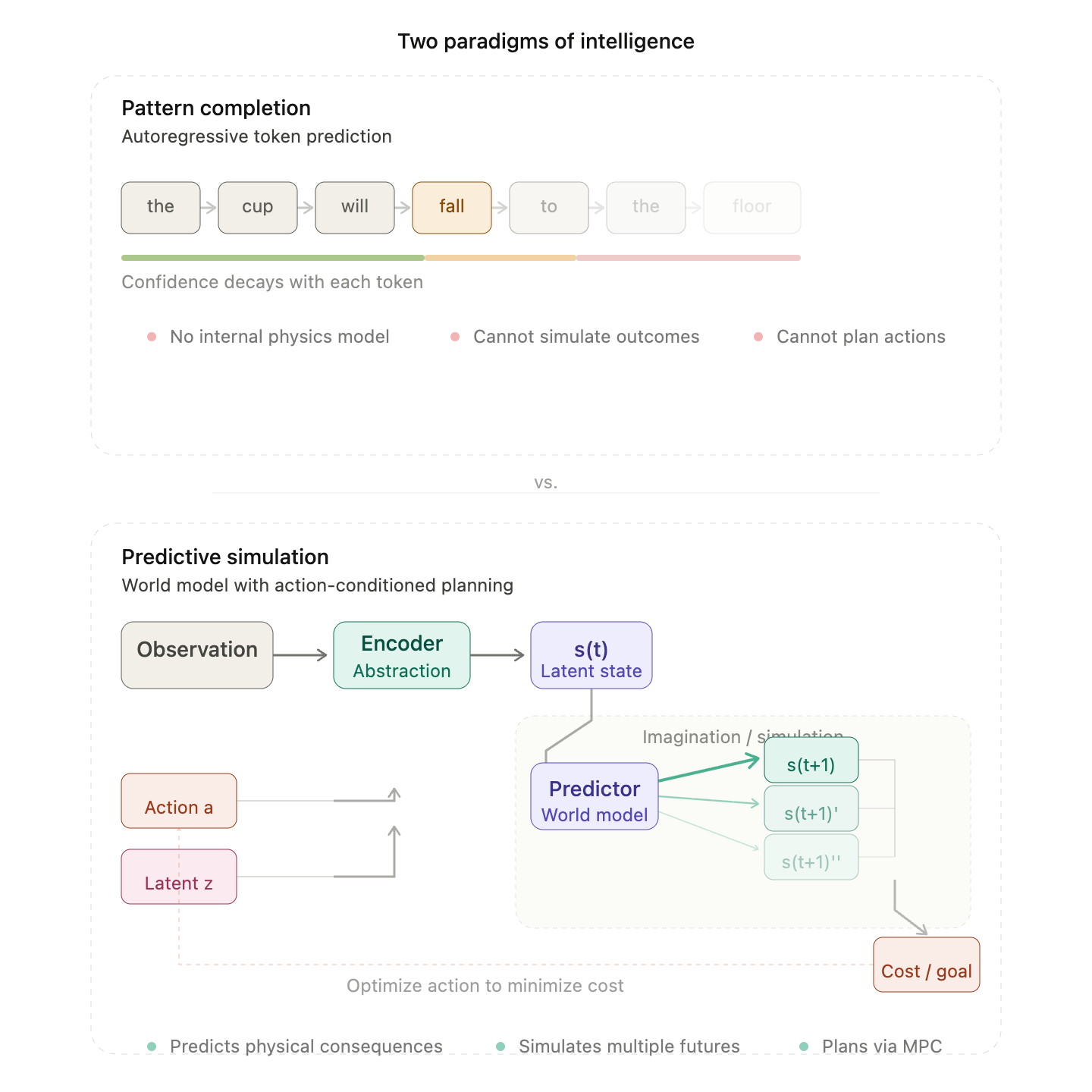
2. What Is a World Model?
A world model is an internal, learnable model of an environment’s dynamics. Given a representation of the current state, an action under consideration, and possibly some latent variables capturing uncertainty, it predicts the next state—not in raw pixels, but in an abstract representation space that retains what matters for planning. Yann LeCun’s precise formulation:
> Given an observation $(x(t))$, a previous state estimate $(s(t))$, an action proposal $(a(t))$, and a latent variable $(z(t))$, a world model computes representation $(h(t) = ext{Enc}(x(t)))$ and prediction $(s(t+1) = ext{Pred}(h(t), s(t), z(t), a(t)))$.
The latent variable $(z)$ allows the model to represent multiple plausible futures—an essential feature because the physical world is inherently uncertain at the fine-grained level. By predicting in latent space, the model can ignore irrelevant details (the exact rustling of leaves) while preserving causally relevant structure (an object’s trajectory after a push).
The Cognitive Principle: Imagination as Simulation
The intellectual lineage of world models goes back to psychologist Kenneth Craik’s 1943 insight that organisms carry a “small‑scale model” of reality in their heads, enabling them to try out actions mentally before committing to them. Modern cognitive science identifies several key computational behaviours that a world model enables:
- Action‑conditioned reasoning: Understanding how interventions change outcomes—not just observing correlations.
- Anticipation: Simulating possible future states under different action sequences.
- Planning: Using the model as a “computational snow globe” to evaluate and optimise action trajectories before execution.
- Structure‑preserving representation: Maintaining a faithful mapping of the world’s topology and causal relationships in latent space.
These capabilities are what turn a pattern recogniser into a reasoner that can handle novel, high‑dimensional, and continuously changing environments—exactly the setting of real‑world robotics and autonomous systems. !WM SVG to Image
{kind=link}
---
3. Zero‑Shot Planning ≠ Zero‑Shot Learning
A crucial distinction must be drawn early, because the two terms are often conflated.
Zero‑Shot Learning (ZSL) is a classification paradigm. A model trained on a given set of classes generalises to recognise instances of entirely new classes at test time, usually by leveraging auxiliary information like semantic attribute vectors or textual descriptions. It does not require the model to act in the world, simulate outcomes, or select motor commands.
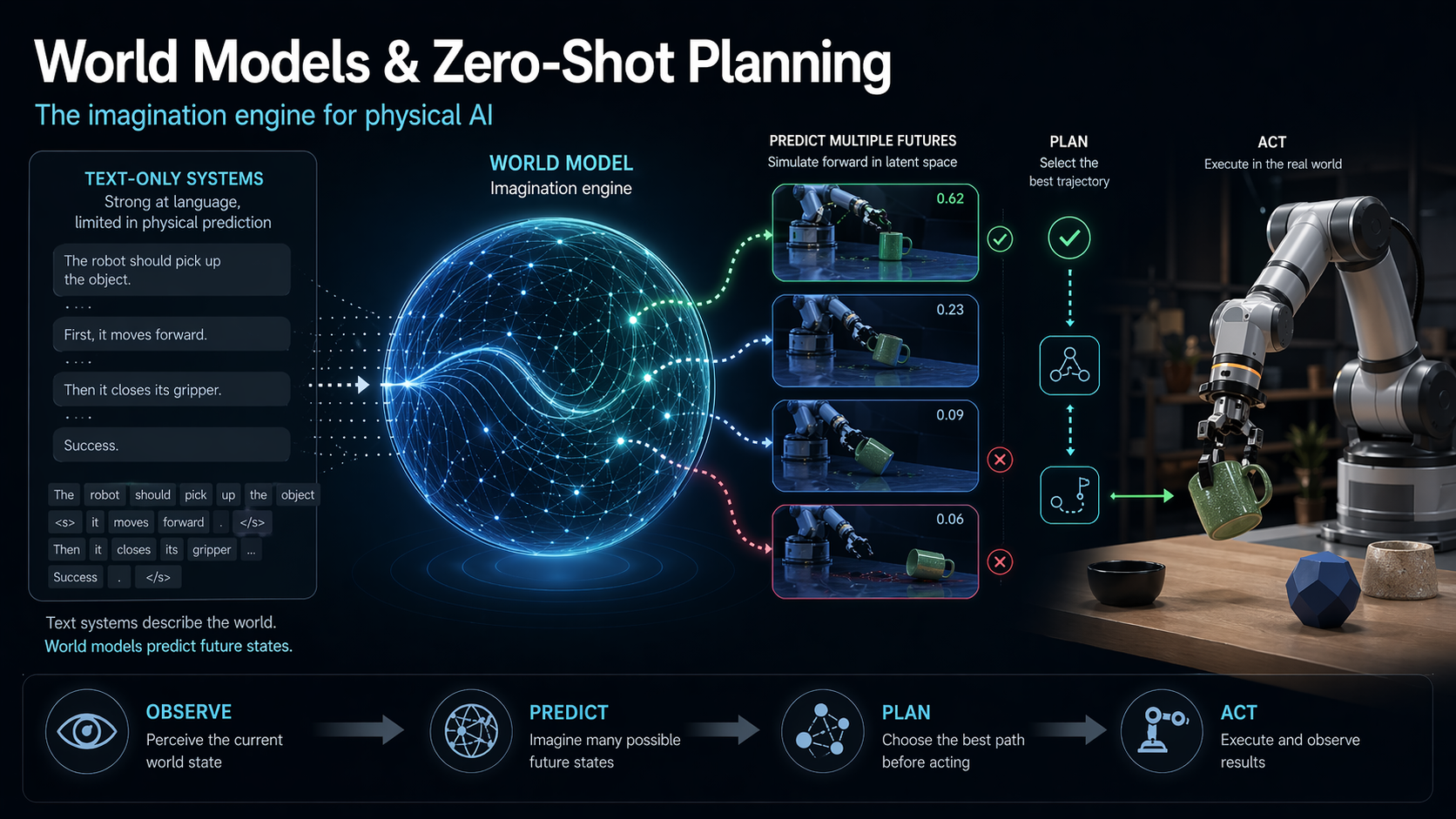
Zero‑Shot Planning (ZSP) is an action paradigm. An agent equipped with a predictive world model is given a goal—frequently a desired visual or latent state—and must generate and execute a sequence of actions to reach that goal without any task‑specific training, reward engineering, or expert demonstrations. The world model itself provides the supervisory signal: the agent uses Model‑Predictive Control (MPC) to propose candidate action sequences, simulate their outcomes, and optimise for the sequence that best matches the goal.
Recent systems demonstrate this concretely. DINO‑WM (Zhou et al., 2025) builds world models on top of pre‑trained visual features (DINOv2) and achieves zero‑shot behavioural solutions across six diverse environments—navigating unseen mazes, manipulating novel objects, and controlling multi‑particle systems—without reward models or inverse models. V‑JEPA 2‑AC (2025) performs zero‑shot pick‑and‑place with novel objects in unseen environments using only 62 hours of unlabeled robot video and no task‑specific fine‑tuning.
The bottom line: zero‑shot planning is what makes world models a genuine leap, not an incremental tweak. It fills the massive voids that training data cannot cover—the long tails of high‑dimensional, noisy real‑world distributions—through online simulation rather than offline memorisation.
---
4. Where Language Models Fit (and Where the Gaps Remain)
LLMs excel at retrieving, recombining, and reasoning over symbolic patterns present in their training corpora. They can describe what happens when a cup falls off a table, and they can even generate plans in natural language. These are significant abilities, and they will remain central to the AI stack.
However, when we move from describing the world to acting within it, the requirements change:
Action‑conditioned, causal‑style reasoning. LLMs predict tokens based on statistical correlations in text. They can tell you that striking a match produces a flame. A world model, conditioned on the action of striking, can simulate the consequences—predicting the flame’s appearance as a state transition. This is not formal causal reasoning in Pearl’s interventionist sense (it remains an open question whether current world models achieve that), but it is a step beyond passive correlation. As LeCun puts it: “Our world models are action‑conditioned, and hence closer to causal intervention than passive sequence prediction.”
Physical and spatial grounding. Text is a low‑bandwidth representation. A young child absorbs roughly $(10^{15})$ bytes of visual information by age four—fifty times more than the largest LLM training sets, and in a modality that directly encodes intuitive physics, object permanence, and spatial relationships. World models trained on video or sensor streams can learn these regularities from observation, providing the grounded common sense that pure language does not reliably confer.
Long‑horizon planning with consistency. Autoregressive generation compounds errors with each added token. Without lookahead or backtracking, a plan’s coherence decays exponentially with length. World models, used with MPC, perform explicit optimisation over future state trajectories, maintaining consistency even over longer horizons—though truly long‑term, hierarchical planning remains an open problem.
Adaptation to unseen physical configurations. LLMs operate primarily within the distribution of their training data. When faced with a novel arrangement of objects, unusual lighting, or adversarial dynamics, they can falter. A world model that understands the mechanics of objects can compose familiar primitives into novel multi‑step solutions—a form of compositional generalisation.
Real‑time knowledge integration. LLMs are static once trained, requiring costly retraining to update. A world model can incorporate streaming sensor data, adjusting its internal representations as the environment changes.
In short: LLMs describe, reason, and suggest. World models simulate, ground, and plan. The two are complementary. The combination—a language model that can query a world model for physical consequences—is one of the most promising directions for building broadly capable embodied agents.
---
5. The Architecture: JEPA, Hierarchical Planning, and Model‑Predictive Control
{kind=link}
5.1 LeCun’s Objective‑Driven Architecture
LeCun’s 2022 proposal for autonomous machine intelligence defines a modular cognitive architecture:
- Perception Module: Encodes raw sensor input into abstract state representations.
- World Model (centerpiece): Predicts $(s(t+1))$ from $(s(t))$ and action $(a(t))$, using latent variables to handle uncertainty. Predictions happen in representation space, not pixel space.
- Actor: Proposes action sequences. Operates in Mode 1 (reactive, fast) and Mode 2 (deliberate planning via world model simulation).
- Cost Module: Intrinsic cost (hard‑wired drives like safety, power) plus a trainable critic that anticipates future costs—much like fear anticipates pain.
- Short‑Term Memory: Stores recent state‑action‑cost triples for online learning.
- Configurator: Executive control that modulates all modules to the current task; analogous to prefrontal cortex function.
5.2 JEPA: Predictive, Not Generative
The Joint Embedding Predictive Architecture (JEPA) implements the world model without attempting to generate pixels. It learns to predict the latent representation of future states from current ones (plus actions and latent variables), discarding unpredictable detail while preserving causally relevant structure. This avoids the computational waste and blurriness that plague pixel‑level generative approaches.
JEPA is trained with non‑contrastive regularisation (e.g., VICReg or Barlow Twins) to prevent representational collapse—ensuring the embedding space is both informative and diverse.
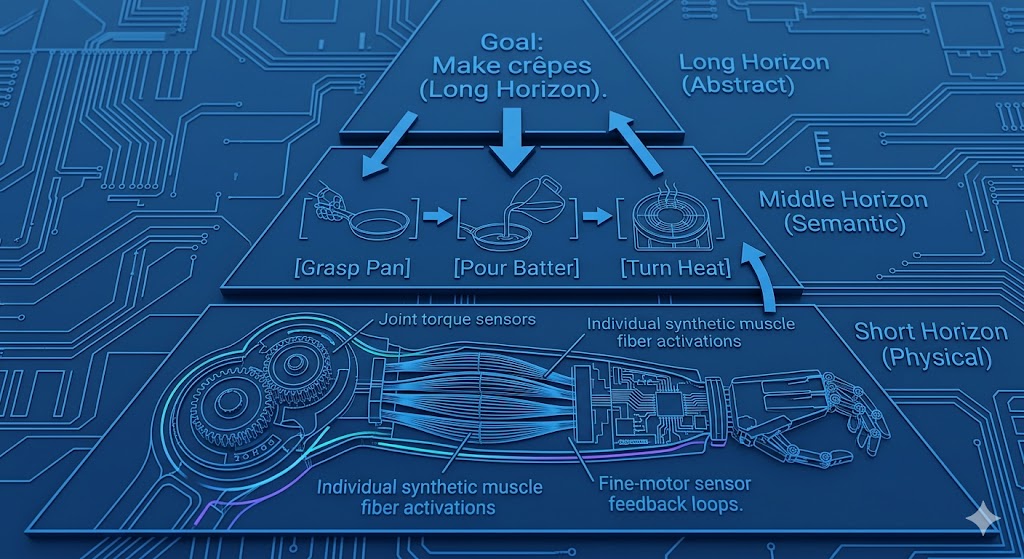
Hierarchical JEPA (H‑JEPA) stacks multiple levels: lower levels make detailed, short‑term predictions; higher levels capture abstract, long‑term transitions. This mirrors human cognition—you can predict your body position milliseconds ahead with precision, but your location an hour from now only abstractly. Each level sets sub‑goals for the one below, making decomposition of complex tasks possible in principle. Autonomous learning of these intermediate abstractions, however, remains unsolved. !World Models hierarchical planning
{kind=link}
5.3 Model‑Predictive Control: The Zero‑Shot Engine
MPC turns a good world model into a zero‑shot planner. The agent uses the world model as a simulator: it generates candidate action sequences, rolls out the predicted states, evaluates the resulting trajectory against a cost or goal‑similarity function, and iteratively refines the plan. No task‑specific learning is needed—planning is the learning.
This is why reinforcement learning (RL) should be a last resort for novel tasks. RL requires enormous numbers of environment interactions to converge; a simulated car might drive off a cliff dozens of times before learning not to. MPC, by contrast, does the trial‑and‑error inside the world model—fast, safe, and data‑efficient. RL retains value for crystallising frequently encountered patterns into fast reactive policies (Mode 1), but for acquiring new behaviours on the fly, planning is far superior.
---
6. The World Model Landscape (Early 2026)
The theoretical promise is now backed by working systems and significant investment.
Key Implementations
- V‑JEPA 2 / V‑JEPA 2‑AC (2025): A ~1B‑parameter ViT‑g trained on over 1 million hours of internet video via VideoMix22M. Achieves 77.3% top‑1 on Something‑Something v2 (fine‑grained motion understanding) and 39.7 recall@5 on Epic‑Kitchens‑100 (action anticipation). The action‑conditioned variant (62 hours of robot video, no task rewards) performs zero‑shot pick‑and‑place on a Franka arm with 65–80% success on novel objects.
- V‑JEPA 2.1 (March 2026): Adds dense predictive loss and deep self‑supervision, improving real‑robot grasping success by 20 points over V‑JEPA 2‑AC. Also state‑of‑the‑art on Ego4D short‑term object‑interaction anticipation.
- DINO‑WM (2025): Constructs world models directly from pre‑trained DINOv2 visual features; demonstrates zero‑shot planning on unseen mazes and manipulation tasks without reward models or expert demos.
- DreamerV3 (Nature, April 2025): First algorithm to collect diamonds in Minecraft from scratch without human data, using a compact latent world model and training entirely within the learned simulator. Demonstrates massive data efficiency gains.
- DreamerV4 (September 2025): Extends Dreamer with a block‑causal transformer architecture and offline video‑action data, further improving scalability.
- Genie 3 (DeepMind, August 2025): A generative world model producing real‑time, interactive 3D environments from text prompts at 24 fps/720p, with multi‑minute consistency.
- NVIDIA Cosmos: Open world foundation model platform trained on 20+ million hours of real‑world video for robotics and AV simulators.
- DreamZero (NVIDIA, February 2026): A 14B‑parameter World Action Model built on a pretrained video diffusion backbone. Achieves 2× improvement over state‑of‑the‑art VLAs on environment/task generalisation and demonstrates cross‑embodiment transfer with only 30 minutes of play data.
- LeWorldModel (AMI Labs, March 2026): Simplified JEPA with provable anti‑collapse guarantees, trained end‑to‑end on consumer GPUs with ~15M parameters.
The Generative vs. Internal Distinction
A critical clarification: “world model” currently means two things.
1. Generative world simulators (Genie 3, World Labs Marble, Cosmos): AI‑powered rendering engines that create visible, interactive 3D environments. 2. Internal predictive models for planning (JEPA, DreamerV3/4, DINO‑WM): Latent‑space predictors that enable agents to imagine action consequences and plan; they may never produce a visible image.
Both are valuable, but they serve different roles. LeCun’s framework is firmly in the second camp—arguing that intelligence does not require generation, only prediction in representation space. Generative world models, meanwhile, function as digital twins and training environments. They are complementary technologies.
Investment and Momentum
AMI Labs (founded by LeCun in late 2025) raised \$1.03 billion in seed funding at a \$3.5 billion pre‑money valuation in March 2026. World Labs (Fei‑Fei Li) added a further \$1 billion in February 2026, with reports of a ~\$5 billion valuation. Overall, over \$34 billion of private capital flowed into robotics‑related companies in 2025—more than double 2024’s figure (PitchBook). The market is betting that grounded physical intelligence is the next platform.
---
7. Challenges, Limitations, and Open Problems
World models are not a solved problem. A balanced account must acknowledge the current frontiers:
- Intuitive physics still lags. On the IntPhys 2 benchmark—which tests object permanence, solidity, and spatio‑temporal continuity—humans achieve near‑perfect accuracy. Current models, including V‑JEPA 2, perform at approximately chance level. We are far from the intuitive physics of a 9‑month‑old infant.
- Short temporal horizons. V‑JEPA 2 processes ~16 seconds of video. Scaling to minutes, hours, or days requires hierarchical abstraction and massive compute.
- Hierarchical planning is unsolved. No system autonomously learns the intermediate abstractions needed to decompose “go to Paris” into progressively concrete sub‑goals down to motor commands.
- Sim‑to‑real gap. Learned simulators are imperfect; transferring plans to physical robots remains challenging.
- The configurator problem. The executive control module that directs attention and task decomposition is still largely unspecified.
- Intrinsic alignment. Designing cost functions that reliably encode human values and safety constraints for long‑horizon autonomous agents is a deep, unsolved challenge. On the positive side, an objective‑driven architecture with explicit cost modules is more auditable than a black‑box autoregressive model.
These are not reasons to dismiss world models; they define the research programme for the next decade.
---
8. Conclusion: Toward a Physical AI Stack
World models fill a specific and crucial gap: they provide the action‑conditioned predictive engine needed for embodied systems to plan, adapt, and act safely in the physical world. They do not replace language models; they ground them. An AI that can both reason about the world in language and simulate its physical dynamics in latent space is far more capable than either alone.
Zero‑shot planning—via MPC on top of a learned world model—is the mechanism that makes this sample‑efficient, generalisable, and practical. It explains why the field is moving away from pure RL for novel task acquisition and why world models are attracting billions in investment.
The road ahead is long. Current models still trip over the most basic intuitive physics that infants grasp effortlessly. Hierarchical reasoning over extended time scales remains an open grand challenge. But the direction is clear: the robot‑rich future will be built not just on language, but on imagination.
---
References
1. Assran, M. et al. (2025). V‑JEPA 2: Self‑Supervised Video Models Enable Understanding, Prediction and Planning. arXiv:2506.09985. https://arxiv.org/abs/2506.09985 2. Zhou, E., Pan, M., LeCun, Y., Pinto, L. (2025). DINO‑WM: World Models on Pre‑trained Visual Features enable Zero‑shot Planning. arXiv:2411.04983. https://arxiv.org/abs/2411.04983 3. Hafner, D. et al. (2025). DreamerV3. Nature, April 2025. https://www.nature.com/articles/s41586-025-08744-2 4. Hafner, D. et al. (2025). DreamerV4. arXiv. https://arxiv.org/abs/2509.12405 5. Parker‑Holder, J. & Fruchter, S. (2025). Genie 3: A new frontier for world models. Google DeepMind Blog. https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ 6. Mur‑Labadia, L. et al. (2026). V‑JEPA 2.1: Unlocking Dense Features in Video Self‑Supervised Learning. arXiv:2603.14482. https://arxiv.org/abs/2603.14482 7. NVIDIA DreamZero. ICLR 2026 Workshop on World Models. 8. LeCun, Y. et al. (2026). LeWorldModel: Stable End‑to‑End Joint‑Embedding Predictive Architecture from Pixels. arXiv:2603.19312. https://arxiv.org/abs/2603.19312 9. Craik, K. (1943). The Nature of Explanation. Cambridge University Press. 10. Vafa et al. (2024). MIT study on transformer representations and navigation. https://computing.mit.edu/news/despite-its-impressive-output-generative-ai-doesnt-have-a-coherent-understanding-of-the-world/ 11. Richens, J. et al. (2025). General agents need world models. PMLR v267. https://proceedings.mlr.press/v267/richens25a.html 12. PitchBook (2026). Robotics investment data. 13. LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. OpenReview.