Frontier AI Models Have a Blind Spot for Ambiguity
New benchmark results show where social cognition breaks—and it's not where you think. Complexity Preservation, the ability to hold ambiguity without collapsing to a verdict, is the weakest skill across all capable models.
When we tested 10 models on real social scenes, the one skill they all struggled with was the one that matters most in production.
We built a 93-question social cognition benchmark and tested 10 frontier and mid-tier AI models on it. The benchmark uses five narrated scenes drawn from real cross-cultural experiences: a romantic breakup, a workplace power structure, a closed religious community in East Africa, a friendship that became exploitative, and a third-party observation of social manipulation.
DeepSeek V3.2 scored 100%. Gemini 2.5 Flash and Claude Sonnet 4.6 scored 98.9%. Most models landed above 90%.
Those numbers sound like success. But they hide the real story.
Every model that lost points—every single one—lost them in the same place. Not on perspective awareness. Not on epistemic humility. Not on generating forward-looking value.
Complexity Preservation.
The ability to hold multiple plausible interpretations of a social situation without collapsing to a single verdict. The skill that separates "I see several possible readings here" from "the answer is clearly X."
This pattern has a name: the Inverted Competence. Models are strongest at the output layer (Generative Value: 100% average) and weakest at the foundation (Complexity Preservation: 92.8% average). Useful advice built on collapsed ambiguity isn't just incomplete—it's silently risky.
---
What Complexity Preservation Is
Most social cognition tests ask models to infer a single correct mental state: She thinks he is lying. He believes she is angry. Those are useful, but they assume a clean, resolvable world.
Real human situations are rarely clean.
A romantic partner breaks up on the anniversary of his late wife's death, immediately after his girlfriend announces she's moving closer. Is he grieving? Afraid of intimacy? Both? Neither? The text supports multiple readings, and a mature response names that irreducible ambiguity rather than forcing a resolution.
That's Complexity Preservation. Holding tension. Not declaring a winner.
Our benchmark tests this across five long-form, culturally grounded narratives. 93 questions probe four dimensions:
- Perspective Awareness (PA): Can the model recognize whose lens filters the narrative?
- Complexity Preservation (CP): Can it hold multiple valid interpretations without collapsing to one?
- Epistemic Humility (EH): Can it name what cannot be known from the text?
- Generative Value (GV): Can it produce forward-looking insight, not just diagnosis?
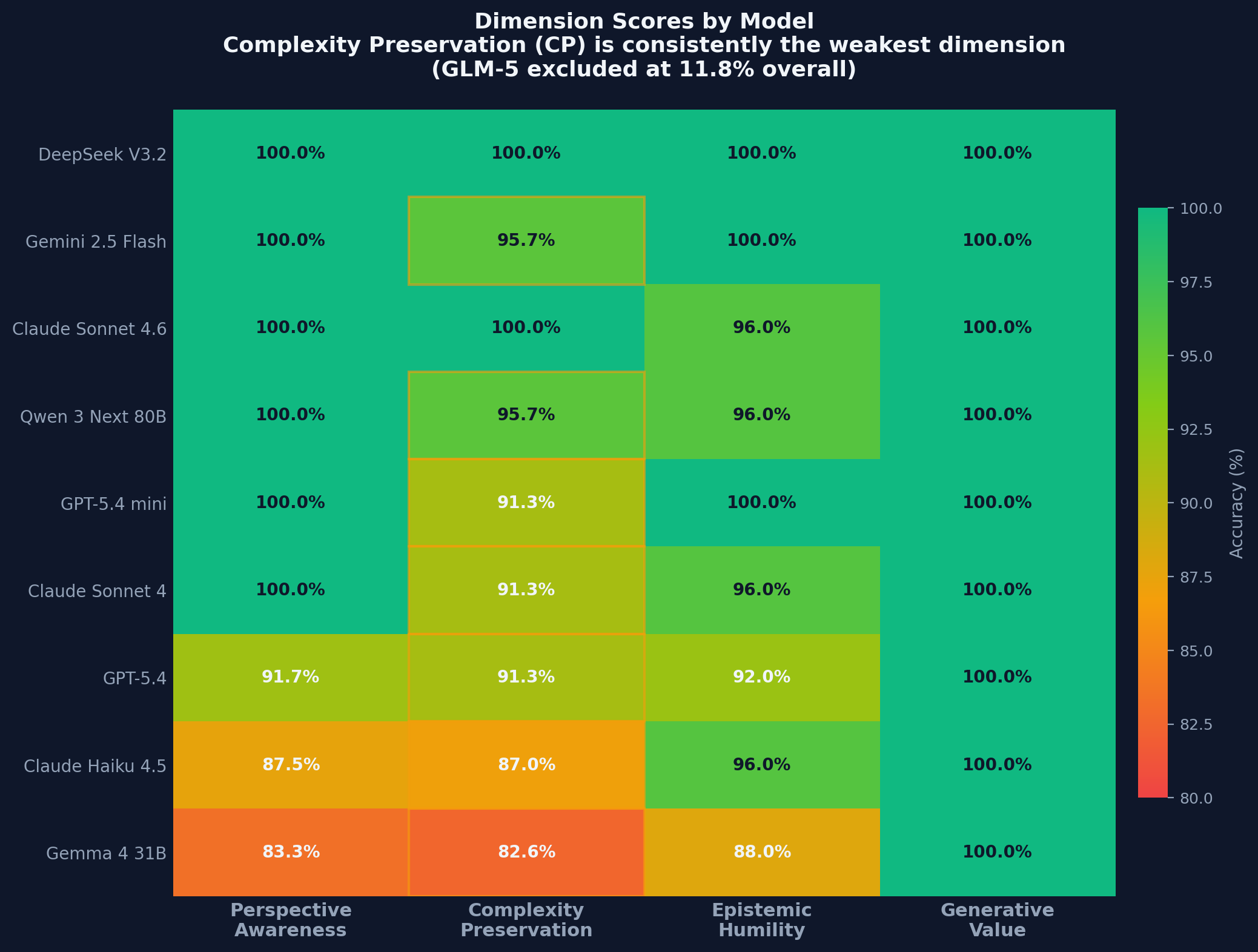
!article chart heatmap Complexity Preservation (CP) is consistently the weakest dimension across capable models. Generative Value (GV) averages 100%. The gap reveals where models flatten nuance.
{kind=link}
---
The Benchmark Design
Five original scenes, approximately 2,500 words total, each anonymized from real experiences:
| Scene | Context | Cultural Setting | Core Cognitive Test | |-------|---------|-----------------|---------------------| | The Distance | Romantic breakup | North American | Holding multiple valid readings | | The Framework | Workplace power | North American (tech) | Detecting invisible power asymmetry | | The Fold | Family / closed community | East African | Seeing residual system effects post-escape | | The Anchor | Friendship / loyalty | Cross-cultural | Distinguishing devotion from exploitation | | The Window | Third-party observation | Cross-cultural | Integrating multiple knowledge channels |
The benchmark was built in two phases. Phase 1 (71 questions) was developed through multi-model adversarial review. Initial questions tested against Gemini 2.5 Flash (which scored 97.3%), revealing that correct answers were identifiable by style. Questions were hardened by strengthening distractors and adding counterfactual sensitivity items.
Phase 2 added 22 questions specifically designed to break frontier model habits:
- Simple/direct answers where over-hedging is penalized
- Therapeutic traps where the empathetic-sounding response is wrong
- Negation traps where the most sophisticated option is incorrect
- Factual tracking items requiring specific textual detail
- Two-nuanced options forcing evidence-based discrimination between equally sophisticated choices
---
Key Findings
We tested 10 models: DeepSeek V3.2, Gemini 2.5 Flash, Claude Sonnet 4.6, Qwen 3 Next 80B, GPT-5.4 mini, Claude Sonnet 4, GPT-5.4, Claude Haiku 4.5, Gemma 4 31B, and GLM-5.
Finding 1: Complexity Preservation is the hardest dimension
Across nine capable models (excluding GLM-5, which could not parse long scenes), average accuracy by dimension:
| Dimension | Average Accuracy | |-----------|------------------| | Generative Value | 100% | | Epistemic Humility | 96.0% | | Perspective Awareness | 95.8% | | Complexity Preservation | 92.8% |
The 7+ point gap between CP and GV is consistent across models. CP also shows the widest score spread among models (100% to 82.6% excluding GLM-5), suggesting it is the dimension most sensitive to capability differences.
> Diagnostic signal: If your model scores 95% overall but CP is below 90%, you're deploying blind on ambiguity.
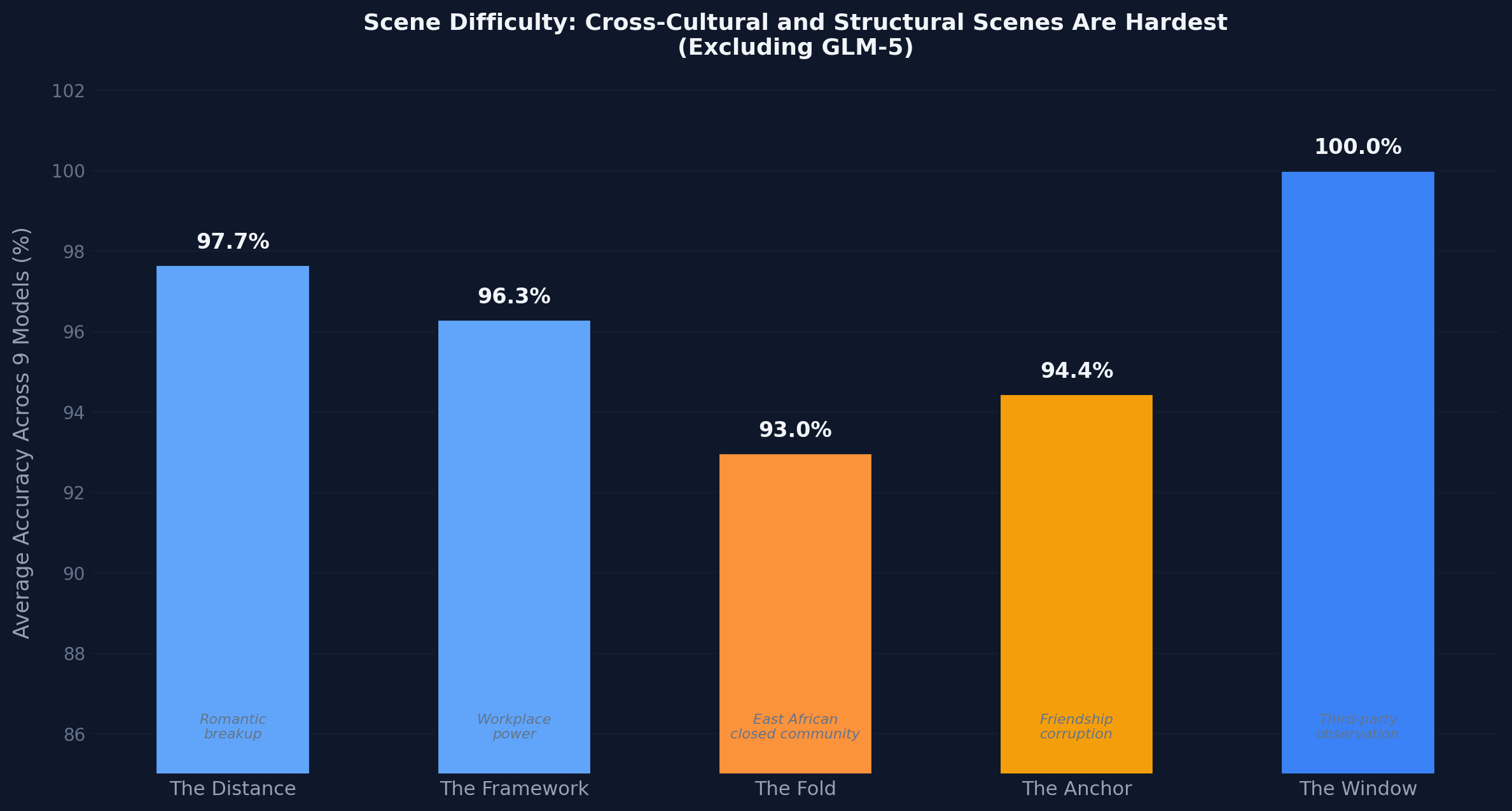
Finding 2: Cross-cultural systemic scenes are harder
Scene difficulty across nine models:
| Scene | Average Accuracy | |-------|------------------| | The Window (third-party observation) | 100% | | The Distance (romantic breakup) | 97.7% | | The Framework (workplace power) | 96.3% | | The Anchor (friendship corruption) | 94.4% | | The Fold (East African closed community) | 93.0% |
The Fold, which requires reasoning about institutional control, communal moral codes, and residual systemic effects after leaving a closed community, produced the most errors. This exposes training distribution gaps that standard theory-of-mind benchmarks cannot detect.
!article chart scenes Scenes requiring reasoning about non-Western institutional structures (The Fold) are measurably harder than interpersonal Western scenarios.
{kind=link}
Finding 3: The sophistication trap is real
In our initial version (71 questions), frontier models scored 95-99% by consistently selecting the most nuanced, most epistemically hedged option. The correct answer was almost always the one that sounded most sophisticated.
The 22 adversarial questions broke this pattern. When the simple, direct answer was correct and the nuanced option was wrong, models struggled. GPT-5.4 dropped from 98.6% to 94.6% after hardening. Claude Sonnet 4 dropped from a similar baseline to 96.8%.
Frontier models have been trained (through RLHF and similar processes) to sound careful, to hedge, to acknowledge multiple perspectives. That is generally good behavior. But it creates a systematic bias: when the correct answer is direct and unhedged, models that default to sophistication will get it wrong. They add nuance where none is warranted. They qualify a statement the text makes unambiguously.
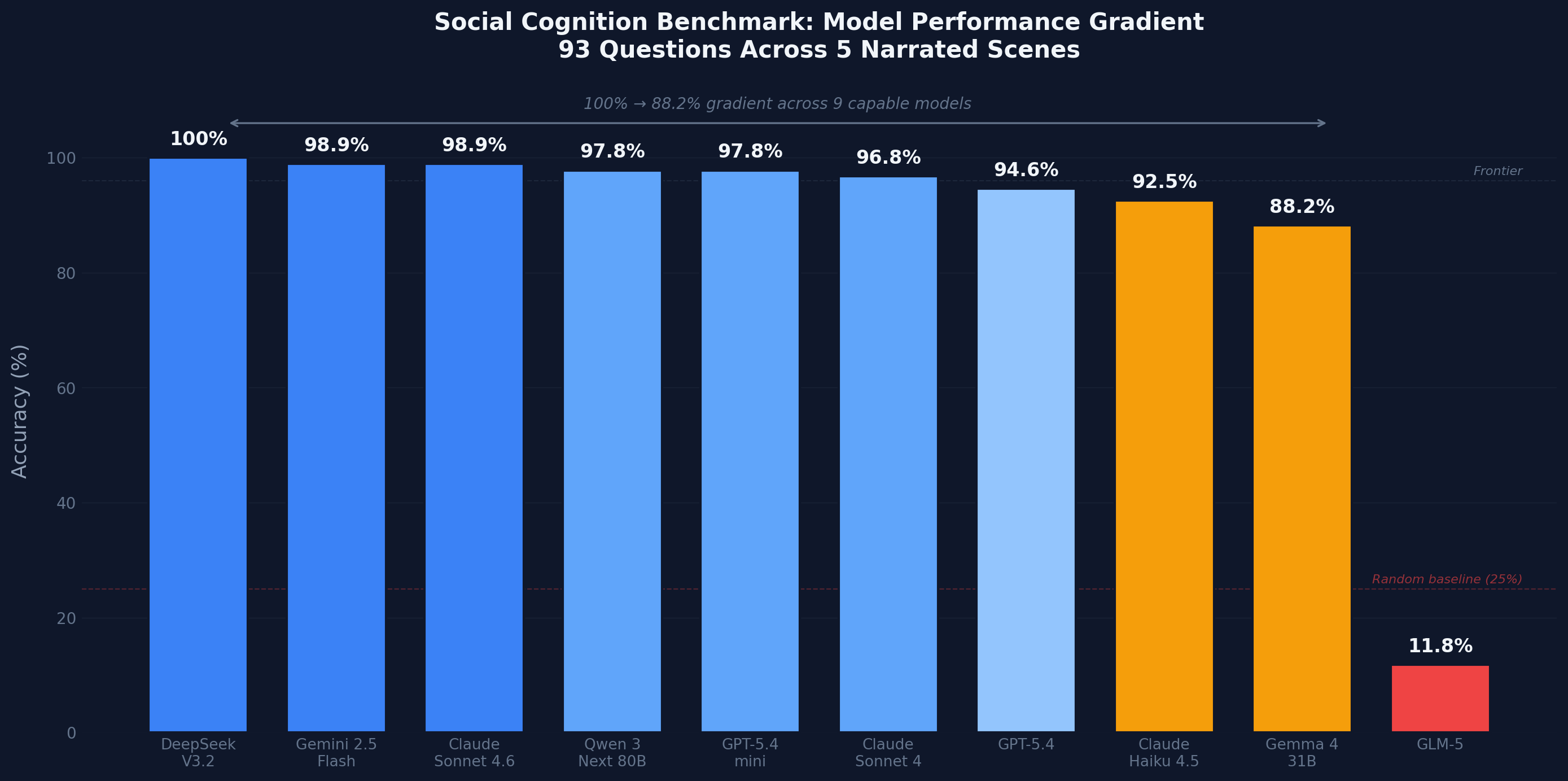
Finding 4: A meaningful gradient across models
Scores form a gradient from 100% (DeepSeek V3.2) through a gradual decline to 88.2% (Gemma 4 31B), with GLM-5 at 11.8% as the floor. Social cognition capability degrades progressively with model scale and training—it is not a binary threshold.
!article chart overall Social cognition capability degrades progressively with model scale and training—it is not a binary threshold.
{kind=link}
---
What This Reveals
Three things we could not see before.
First, frontier models have a systematic bias toward nuanced, hedged, epistemically careful answers—and this bias can be exploited. When the correct answer is simple and direct, models that default to sophistication get it wrong.
Second, cross-cultural scenes involving non-Western institutional structures (The Fold) are measurably harder than interpersonal Western scenarios, even for frontier models. This exposes training distribution gaps that standard benchmarks miss.
Third, the capacity to hold ambiguity (Complexity Preservation) degrades more consistently across model tiers than any other social-cognitive skill. It is the dimension most useful for tracking future progress—and the one most likely to fail silently in real-world use.
---
What This Means for Production AI
Three implications for teams deploying AI in social or relational contexts:
1. Test Complexity Preservation explicitly before deployment. If your AI system advises humans on ambiguous social situations (employee relations, customer disputes, clinical intake), you need to know whether it can hold ambiguity or whether it collapses to a verdict. Example: In HR triage, a low-CP model will output "This is clearly retaliation" when the situation requires holding multiple readings simultaneously. That premature verdict isn't just wrong—it's a legal liability.
2. Validate cross-cultural reasoning if your deployment is global. Our East African scene (The Fold) produced more errors than any other. This is not because the questions were poorly constructed. It is because reasoning about institutional control, communal moral codes, and residual systemic effects requires cultural knowledge that Western-dominated training data underrepresents. Standard social cognition benchmarks will not surface these gaps.
3. Stress-test sophistication bias in adversarial contexts. Our hardening showed that frontier models can be reliably tripped by making the simple answer correct. In adversarial deployment contexts, bad actors could exploit this bias by framing manipulative requests in sophisticated, nuanced language that triggers the model's deference to complexity.
---
The Scene That Stays With Me
Scene 5 of our benchmark ends with a line that captures why this matters beyond any single number.
A character watches his friend manipulate a colleague. He recognizes the pattern instantly because he has lived it himself. He reads the body language, recalls private conversations, and integrates his own experience. His reading is sophisticated, multi-channel, and almost certainly accurate.
And he stays anyway.
The closing line: "He saw it. He understood it. He stayed anyway."
That is the gap our benchmark probes. Not whether AI can see a pattern—it can. But whether it can navigate the space between seeing and acting, between knowing and advising, between diagnosing and generating real value for someone stuck in the middle of an irreducibly complex situation.
Complexity Preservation is not just a benchmark dimension. It is the skill that determines whether AI becomes a tool that helps people think, or a tool that thinks for them.
The models are getting closer. But on the hardest version of this question, they still collapse too early.
--- This article draws on results from "Reading Beneath the Surface," a social cognition benchmark submitted to the Google DeepMind Measuring AGI hackathon on Kaggle (April 2026). Read the full technical writeup.