The Hardware Bet You Can't Actually Audit
At the scale of modern AI clusters, hardware failure isn't dramatic. It's silent. And most CTOs are approving infrastructure without knowing how to detect it.
A training run that crashes is expensive, but it is at least honest. The job dies. The logs light up. Engineers triage, recover, and move on. Everyone involved knows a failure happened.
The more dangerous failure is the one that keeps moving.
That is the asymmetry most AI infrastructure discussions still miss. A cluster can continue training. An inference system can continue serving. Dashboards can stay green. The application can appear healthy. And somewhere inside that stack, a faulty device can be producing incorrect computations with no hardware alarm and no obvious application-level signal. The system does not stop. It simply becomes wrong.
Consider the scale at which this is now happening. Meta disclosed in its Llama 3 paper that a 16,384 H100 GPU cluster experienced 466 job interruptions over 54 days. One failure every three hours, on average. Of those, 419 were unexpected. Roughly 78 percent of the unexpected interruptions traced to hardware, and GPU issues accounted for 58.7 percent of all unexpected issues. Meta describes the system as far less fault-tolerant than the CPU clusters it had operated before, because a single GPU failure could require restarting the whole job.
Those are the failures Meta could see.
The number Meta cannot report in the same paper is the one that should keep infrastructure leaders awake: how many computations completed, how many checkpoints were written, how many inference responses were returned, while a defective component stayed below the threshold of obvious failure. That is the bet behind modern AI infrastructure. Not whether hardware will fail. Whether the organization will know when hardware is wrong without being noisy enough to crash.
That is no longer a narrow reliability topic. It is a governance problem inside the capital stack. The organizations buying AI infrastructure today are approving hardware, software, and data-center decisions that assume correctness unless disproven. At current cluster sizes, that assumption is doing more work than most procurement processes acknowledge.
The Math of Inevitability
There is a point where scale stops being a multiplier and becomes a category change.
A 100-GPU cluster and a 10,000-GPU cluster are not the same engineering problem with an extra zero attached. At smaller scale, hardware defects can remain rare enough that teams experience them as exceptions. At larger scale, rare defects become routine simply because the fleet is large enough to surface them continuously. The practical question changes from "will this happen?" to "how often is this happening somewhere in the system right now?"
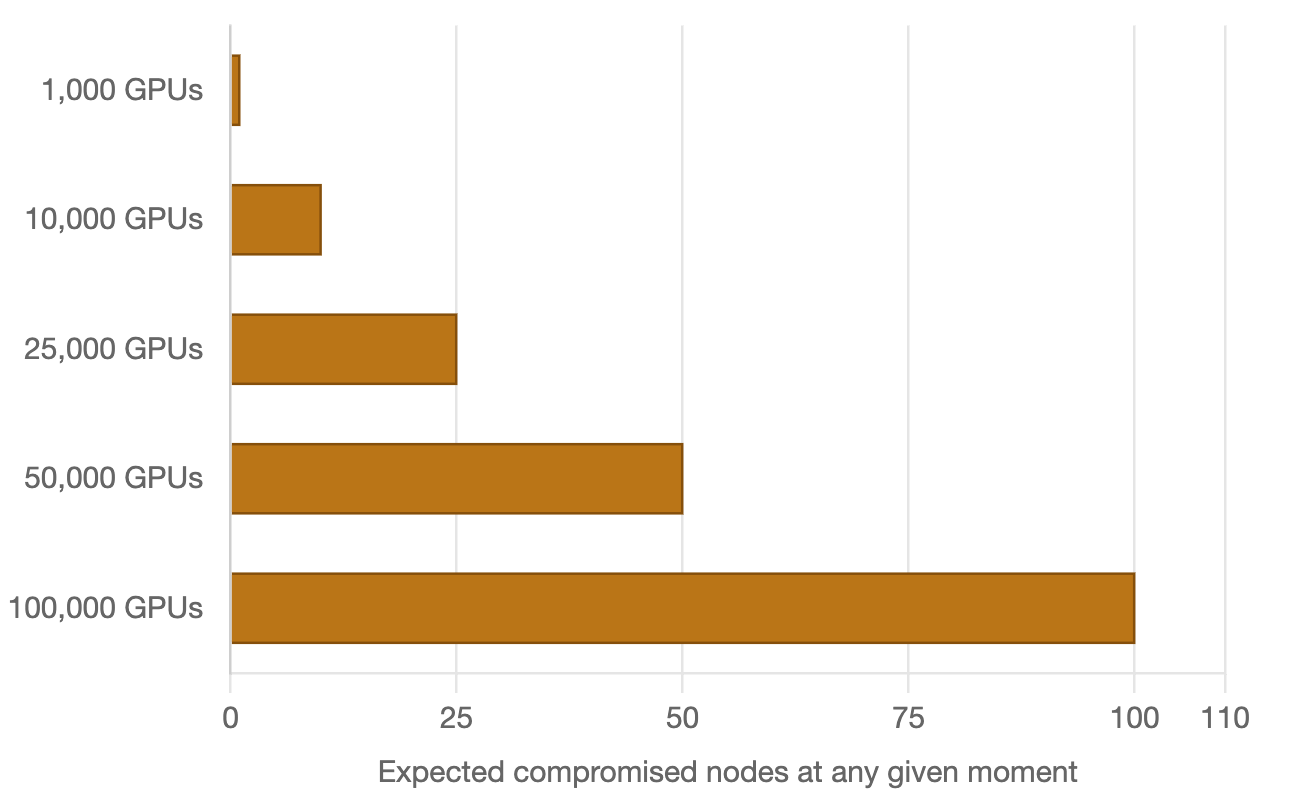
Google's 2021 paper "Cores That Don't Count" named the problem directly. It describes "mercurial cores" — processors that produce correct results most of the time but intermittently return erroneous computations. These failures are silent, difficult to root-cause, highly dependent on specific instruction sequences, and likely to remain a fact of life that must be detected and isolated in production rather than assumed away at manufacturing. Fleet-wide, Google observed these defects at roughly 1 in every 1,000 machines. Not catastrophic failure. Not thermal shutdown. Quiet, intermittent, computationally wrong output with no error signal.
Apply that rate to the clusters being built and procured today. At 10,000 GPUs, the expected number of machines producing intermittent silent errors at any given time is approximately 10. At 100,000 GPUs, it is approximately 100. These are not edge cases. They are the statistical baseline.
{kind=link}
The physics reinforces the math. Modern AI accelerators are manufactured at sub-5nm process nodes. At these geometries, transistor behavior becomes measurably less deterministic. Smaller transistors are more susceptible to voltage fluctuations, cosmic ray interference, and manufacturing variability that falls within acceptable tolerances but still produces occasional computational errors. Each new process node delivers more performance per watt. Each new process node also narrows the margin between correct and incorrect computation.
This is the Math of Inevitability. Not a formal equation. A strategic intuition. If a defect class is rare but real, and you keep increasing the number of devices, the duration of workloads, the width of memory paths, and the sensitivity of applications to small numeric deviations, then eventually you cross from "possible" to "operationally certain." That is what modern AI clusters are doing.
The hardware context makes that more, not less, important. HBM4 doubles the memory interface width to 2,048 bits, doubles the number of independent channels per stack from 16 to 32, supports up to 2 TB/s of bandwidth per stack, and reaches up to 64 GB in a 16-high stack. Those are extraordinary capabilities. They also mean more concurrency, more density, and more places where correctness has to be preserved, not merely performance extracted.
That is why silent corruption belongs in the same sentence as scale, not after it.
What Silent Failure Actually Looks Like
Three different failure modes in AI systems are routinely conflated, and the conflation is dangerous because it obscures the one that has no established mitigation in most deployments. !three failure modes ai infrastructure
{kind=link}
The first is the visible training failure. A host drops. A GPU fails. NVLink misbehaves. A job restarts. Meta's Llama 3 paper is largely about this visible class of interruptions. They are painful, but they are legible. Engineers know something went wrong because the system stops behaving as expected.
The second is model hallucination. That is a model-level behavior. The model produces plausible but incorrect content because generation is probabilistic, context is incomplete, retrieval is weak, or the model simply predicts the wrong continuation. This is the kind of failure most executives now recognize. It lives at the behavior layer.
The third is much lower in the stack and much harder to reason about. Silent hardware corruption means a device produces mathematically incorrect results during computation, those results propagate upward, and nothing in the hardware path necessarily raises its hand. The application may continue. The model may continue training. An inference service may continue returning outputs. And now the organization is debugging behavior that may not be a model problem at all.
That distinction matters because the mitigations are entirely different.
You cannot fine-tune your way out of silent corruption. You cannot prompt-engineer around it. You cannot rely on application-level observability alone if the corruption occurs below the layer where your monitoring is looking. Google's paper gives concrete examples of what this class of failure looks like in practice: corrupted database indexes, deterministic mis-computation in AES, repeated data corruption patterns, wrong answers that only appear on specific cores under specific instruction sequences. That is not the model making something up. That is computation itself becoming conditionally unreliable.
This is why the phrase I keep coming back to is the Silent Hallucination Problem.
Most people hear "hallucination" and think about a chatbot saying something false. That is the familiar version. The more dangerous version is lower down. The hardware can, under the wrong conditions, hallucinate a result into the computation path and hand it upward as if it were correct. When that happens in inference, a corrupted device can affect large numbers of consumers, with consequences reaching recommendation systems, privacy policies, integrity checks, and LLM outputs. In training, the same corruption creates an illusion of forward progress, where the system appears to continue productively even while errors accumulate into later degradation.
That is the failure mode that does not announce itself. It simply degrades trust while preserving the appearance of throughput.
Meta, Google, and What the Hyperscalers Already Know
The public evidence base is stronger than most procurement conversations imply.
Start with Meta. During that 54-day Llama 3 training window, Meta experienced one interruption roughly every three hours. The breakdown is especially useful. About 78 percent of unexpected interruptions were tied to hardware. GPU issues were the largest category. Another 17.2 percent originated specifically from HBM3 memory failures. NVLink and other GPU-adjacent failures accounted for an additional 30.1 percent. Only 2 CPU failures occurred in the entire period, a stark contrast that illustrates how disproportionately fragile the GPU and memory subsystems are relative to the rest of the compute stack. Meta also states that the complexity and failure scenarios of 16K GPU training surpassed those of much larger CPU clusters it had run before. That matters because it places the fragility in the architecture of modern AI training itself, not in an isolated operational mishap.
Then look at Google and adjacent hyperscale research. "Cores That Don't Count" does not present silent corruption as an exotic corner case. It presents it as a distinct operational problem caused by mercurial cores that miscompute intermittently, often only under certain instruction sequences, and are difficult to catch through traditional production testing alone. The companion "Silent Data Corruptions at Scale" work adds the fleet reality: across hundreds of thousands of machines, operators found hundreds of CPUs with these defects and concluded that reducing the risk requires not only hardware resiliency but production detection and fault-tolerant software. In plain language, the hardware cannot be treated as a perfect black box.
NVIDIA's 2025 OCP whitepaper on SDC in AI extends the analysis into current AI systems. Two findings matter most for infrastructure leaders. First, the belief that training workloads are naturally self-resilient is only true for a fairly small subset of possible corruption patterns. Second, inference has its own failure profile, and in some ways the harder one. The workload runs at enormous scale, a corrupted device can affect large numbers of consumers, and smaller deviations may be harder to notice than obvious blowups. The paper also reports that analytical detection approaches have outperformed test-based approaches by 41 percent across architectures, applications, and data centers.
Memory standards are starting to reflect the same reality. JEDEC's HBM4 specification, released in April 2025, introduces a 12nm logic base die at the bottom of the memory stack. This is the first HBM generation with true logic integration at the base layer, and it enables on-die memory scrubbing as an explicit SDC mitigation. The memory subsystem itself is becoming a participant in trust, not just a passive supplier of bandwidth. When memory vendors architect for a problem at the transistor level, it is no longer a theoretical concern.
One pattern connects these disclosures. Meta, Google, NVIDIA, Samsung, SK Hynix, and others are all represented in the public OCP work on this topic. The operators closest to the problem are already collaborating around detection and mitigation. The buyers farther downstream often are not. That is the story. The asymmetry between what builders know and what buyers know is the central governance gap in AI infrastructure today.
What I See in Procurement Decisions
In the rooms where infrastructure bets get made, I watch leaders evaluate proposals on performance per dollar and time-to-compute. They ask almost nothing about how corruption is detected, contained, or disclosed. Procurement frameworks designed for earlier compute generations assumed hardware reliability could be taken for granted. Those checklists have not caught up to what modern cluster operators already know.
I see the same pattern repeat. A large enterprise finalizes a hundred-thousand-GPU order. The RFP focuses on FLOPS, power efficiency, and delivery timeline. Questions about silent data corruption rates or continuous verification mechanisms rarely appear. The vendor responds with standard reliability claims. The deal closes. The organization has just placed a bet it cannot audit.
This is, in effect, the procurement logic of the 2010s applied to infrastructure that has outgrown it. Servers had ECC memory, redundant power supplies, and RAID storage. Failures were loud. The assumption that hardware either worked correctly or failed visibly was close enough to true that it could be treated as true. That assumption has not survived the transition to AI-scale compute. A cluster of 100,000 GPUs running at sub-5nm geometries, with HBM memory stacks handling bandwidth measured in terabytes per second, operates in a regime where intermittent silent corruption is a statistical certainty.
The money involved makes the gap harder to excuse. The global AI hardware market is valued at roughly $86.7 billion. Hyperscaler AI infrastructure capital expenditure is projected at approximately $450 billion for 2026. NVIDIA holds around 90 percent share of AI accelerator spending. The capital base is now large enough that silent correctness risk should be discussed as part of the investment case, not treated as an engineering footnote.
I draw a hard line between two postures.
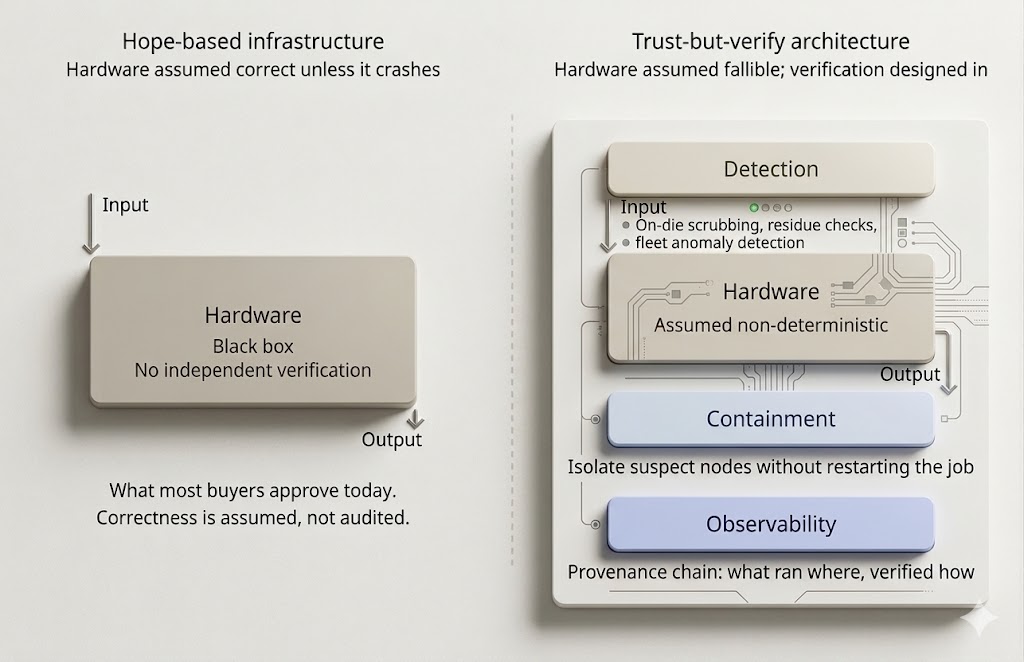
One is Hope-Based Infrastructure. The organization assumes the vendor has handled the hard part, assumes errors will announce themselves if they matter, and assumes the application layer will surface anything important. That is not a strategy. It is optimism disguised as procurement.
The other is Trust-But-Verify Infrastructure. The organization still trusts the vendor, but it does not outsource correctness as a blind faith exercise. It expects evidence, instrumentation, containment, and auditability. It assumes hardware is powerful, fallible, and non-deterministic enough at scale that verification has to be designed in. !381c7a23 2e86 4593 90a3 506454af38d1
{kind=link}
That posture shift is going to separate mature buyers from everyone else.
The Trust-But-Verify Architecture
Trust-but-verify is not a product you purchase. It is an architectural posture that shapes how infrastructure is designed, deployed, and operated. It rests on three capabilities that must be built, not bought.
Detection is the foundation. Continuous verification of computational correctness at the hardware and cluster level, running alongside production workloads rather than in periodic offline sweeps. HBM4's logic base die represents one layer of this: the 12nm integrated logic enables on-die memory scrubbing that identifies and corrects corruption within the memory stack before corrupted data reaches the GPU. At the compute layer, residue-checking mechanisms can verify arithmetic results without fully recomputing them. At the fleet level, the anomaly detection patterns Google pioneered for mercurial cores identify nodes whose outputs diverge statistically from peers running identical workloads. NVIDIA's finding that analytical detection outperforms test-based detection by 41 percent suggests the field is converging on continuous, workload-integrated verification rather than periodic test suites.
Containment determines whether a detected corruption event remains local or propagates. The architectural goal is isolation: when a node is identified as producing suspect results, it is removed from the active pool without restarting the entire job. This requires infrastructure that treats node failure, including silent failure, as a routine event rather than an exceptional one. Google's optical circuit switching represents the most advanced public approach, enabling dynamic reconfiguration of cluster topology so that a suspect node can be excised and its workload redistributed while the rest of the job continues. Most enterprises do not have this capability. Their alternative is re-running entire jobs when corruption is suspected, which turns every detection event into an expensive recovery.
Observability closes the loop. It is not logging in the traditional sense. It is a provenance chain for computational correctness. An audit trail that documents what computation ran, on which physical hardware, at what time, and with what verification status. When a model produces an unexpected output six months after training, the question "was the hardware that trained this model verified as correct during training?" should be answerable. For most organizations today, it is not.
These three capabilities compound. Detection without containment means you know about corruption but cannot limit its blast radius. Containment without observability means you can isolate a node but cannot retroactively assess whether past workloads on that node were affected. Observability without detection means you have an audit trail of unverified computation. All three together constitute an architecture that acknowledges physical reality: at this scale, corruption happens, and the system is designed to find it, limit it, and prove what was clean.
What CTOs Should Actually Be Asking Their Vendors
Once the problem is framed correctly, the vendor conversation changes. I would not walk into an infrastructure review asking only about throughput, total cost of ownership, or model performance. I would ask five much more revealing questions.
What is the documented silent data corruption rate in your fleet, how is it measured, and how often is it reviewed? A serious operator may not disclose everything publicly, but they should have a coherent internal answer. Google published a rate of roughly 1 in 1,000 machines. A vendor who claims zero is either not measuring or not disclosing. If the response collapses back into generic uptime metrics, that tells you the conversation has not reached the right layer.
Which detection mechanisms run continuously, and which only run on demand or during scheduled screening? The distinction matters because intermittent faults often hide between scheduled tests. NVIDIA's data showing a 41 percent advantage for analytical approaches over test-based methods gives this question empirical grounding. You want to know what percentage of the system's capacity is dedicated to verification, and you want to know whether verification is a first-class workload or an afterthought.
When corruption is detected, what is the containment path for my workload? Does the system quarantine a core, a GPU, a host, a rack? Does the job restart fully, resume partially, or keep running while degraded capacity is routed around? If the answer is vague, then recovery may still be more manual than the architecture diagram suggests.
What audit trail do I receive for a given training run or inference workload? I would want to know what hardware provenance is available, what verification metadata is retained, and whether I can reconstruct where a computation executed if a correctness incident appears later. For regulated environments, that is not an engineering luxury. It is a control requirement.
How has this problem changed as your fleet has scaled and as hardware generations have advanced? This question forces a mature operator to discuss trend, not just status. Silent corruption is not a static issue. It changes with workload shape, process technology, packaging complexity, device density, and runtime behavior. A vendor that can discuss that evolution plainly is usually telling you something useful about its engineering culture.
I do not ask these questions because I expect neat answers to all of them. I ask because the quality of the answer tells you whether the provider is operating a real verification discipline or selling confidence as a substitute for one.
Reliability is no longer just an SRE concern. It is becoming a procurement criterion. The infrastructure leaders who will make the strongest bets from 2028 through 2030 are the ones treating hardware as non-deterministic enough today that software, operations, and governance all have to participate in verification.
A clean benchmark result is not proof. A stable dashboard is not proof. A completed run is not proof.
The question is not whether your infrastructure will ever produce corrupted outputs. At this scale, the evidence already points the other way. The question is whether you are architected to know when it happens, isolate it when it does, and defend the computation after the fact. CTOs approving AI infrastructure without that layer are not making a simple hardware purchase. They are making a strategic bet they cannot actually audit.